How to configure HTTP load balancer with HAProxy on Linux
Last updated on December 4, 2020 by Dan Nanni
Increased demand on web based applications and services are putting more and more weight on the shoulders of IT administrators. When faced with unexpected traffic spikes, organic traffic growth, or internal challenges such as hardware failures and urgent maintenance, your web application must remain available, no matter what. Even modern devops and continuous delivery practices can threaten the reliability and consistent performance of your web service.
Unpredictability or inconsistent performance is not something you can afford. But how can we eliminate these downsides? In most cases a proper load balancing solution will do the job. And today I will show you how to set up HTTP load balancer using HAProxy.
What is HTTP load balancing?
HTTP load balancing is a networking solution responsible for distributing incoming HTTP or HTTPS traffic among servers hosting the same application content. By balancing application requests across multiple available servers, a load balancer prevents any application server from becoming a single point of failure, thus improving overall application availability and responsiveness. It also allows you to easily scale in/out an application deployment by adding or removing extra application servers with changing workloads.
Where and when to use load balancing?
As load balancers improve server utilization and maximize availability, you should use it whenever your servers start to be under high loads. Or if you are just planning your architecture for a bigger project, it's a good habit to plan usage of load balancer upfront. It will prove itself useful in the future when you need to scale your environment.
What is HAProxy?
HAProxy is a popular open-source load balancer and proxy for TCP/HTTP servers on GNU/Linux platforms. Designed in a single-threaded event-driven architecture, HAproxy is capable of handling 10G NIC line rate easily, and is being extensively used in many production environments. Its features include automatic health checks, customizable load balancing algorithms, HTTPS/SSL support, session rate limiting, etc.
What are we going to achieve in this tutorial?
In this tutorial, we will go through the process of configuring a HAProxy-based load balancer for HTTP web servers.
Prerequisites
You will need at least one, or preferably two web servers to verify functionality of your load balancer. We assume that backend HTTP web servers are already up and running.
Install HAProxy on Linux
For most distributions, we can install HAProxy using your distribution's package manager.
Install HAProxy on Debian
In Debian we need to add backports for Wheezy. To do that, please create a new file called backports.list in /etc/apt/sources.list.d with the following content:
deb http://cdn.debian.net/debian wheezybackports main
Refresh your repository data and install HAProxy.
# apt get update # apt get install haproxy
Install HAProxy on Ubuntu
# apt get install haproxy
Install HAProxy on CentOS and RHEL
# yum install haproxy
Configure HAProxy
In this tutorial, we assume that there are two HTTP web servers up and running with IP addresses 192.168.100.2 and 192.168.100.3. We also assume that the load balancer will be configured at a server with IP address 192.168.100.4.
To make HAProxy functional, you need to change a number of items in /etc/haproxy/haproxy.cfg. These changes are described in this section. In case some configuration differs for different GNU/Linux distributions, it will be noted in the paragraph.
1. Configure Logging
One of the first things you should do is to set up proper logging for your HAProxy, which will be useful for future debugging. Log configuration can be found in the global section of /etc/haproxy/haproxy.cfg. The following are distro-specific instructions for configuring logging for HAProxy.
Configure Logging on CentOS or RHEL:
To enable logging on CentOS/RHEL, replace:
log 127.0.0.1 local2
with:
log 127.0.0.1 local0
The next step is to set up separate log files for HAProxy in /var/log. For that, we need to modify our current rsyslog configuration. To make the configuration simple and clear, we will create a new file called haproxy.conf in /etc/rsyslog.d/ with the following content.
$ModLoad imudp $UDPServerRun 514 $template Haproxy,"%msg%n" local0.=info /var/log/haproxy.log;Haproxy local0.notice /var/log/haproxystatus.log;Haproxy local0.* ~
This configuration will separate all HAProxy messages based on the $template to log files in /var/log. Now restart rsyslog to apply the changes.
# service rsyslog restart
Debian or Ubuntu:
To enable logging for HAProxy on Debian or Ubuntu, replace:
log /dev/log local0 log /dev/log local1 notice
with:
log 127.0.0.1 local0
Next, to configure separate log files for HAProxy, edit a file called haproxy.conf (or 49-haproxy.conf in Debian) in /etc/rsyslog.d/ with the following content.
$ModLoad imudp $UDPServerRun 514 $template Haproxy,"%msg%n" local0.=info /var/log/haproxy.log;Haproxy local0.notice /var/log/haproxystatus.log;Haproxy local0.* ~
This configuration will separate all HAProxy messages based on the $template to log files in /var/log. Now restart rsyslog to apply the changes.
# service rsyslog restart
2. Setting Defaults
The next step is to set default variables for HAProxy. Find the defaults section in /etc/haproxy/haproxy.cfg, and replace it with the following configuration.
defaults
log global
mode http
option httplog
option dontlognull
retries 3
option redispatch
maxconn 20000
contimeout 5000
clitimeout 50000
srvtimeout 50000
The configuration stated above is recommended for HTTP load balancer use, but it may not be the optimal solution for your environment. In that case, feel free to explore HAProxy man pages to tweak it.
3. Webfarm Configuration
Webfarm configuration defines the pool of available HTTP servers. Most of the settings for our load balancer will be placed here. Now we will create some basic configuration, where our nodes will be defined. Replace all of the configuration from frontend section until the end of file with the following code:
listen webfarm *:80
mode http
stats enable
stats uri /haproxy?stats
stats realm Haproxy Statistics
stats auth haproxy:stats
balance roundrobin
cookie LBN insert indirect nocache
option httpclose
option forwardfor
server web01 192.168.100.2:80 cookie node1 check
server web02 192.168.100.3:80 cookie node2 check
The line listen webfarm *:80 defines on which interfaces our load balancer will listen. For the sake of the tutorial, I've set that to * which makes the load balancer listen on all our interfaces. In a real world scenario, this might be undesirable and should be replaced with an interface that is accessible from the internet.
stats enable stats uri /haproxy?stats stats realm Haproxy Statistics stats auth haproxy:stats
The above settings declare that our load balancer statistics can be accessed on http://<load-balancer-IP>/haproxy?stats. The access is secured with a simple HTTP authentication with login name haproxy and password stats. These settings should be replaced with your own credentials. If you don't need to have these statistics available, then completely disable them.
Here is an example of HAProxy statistics.
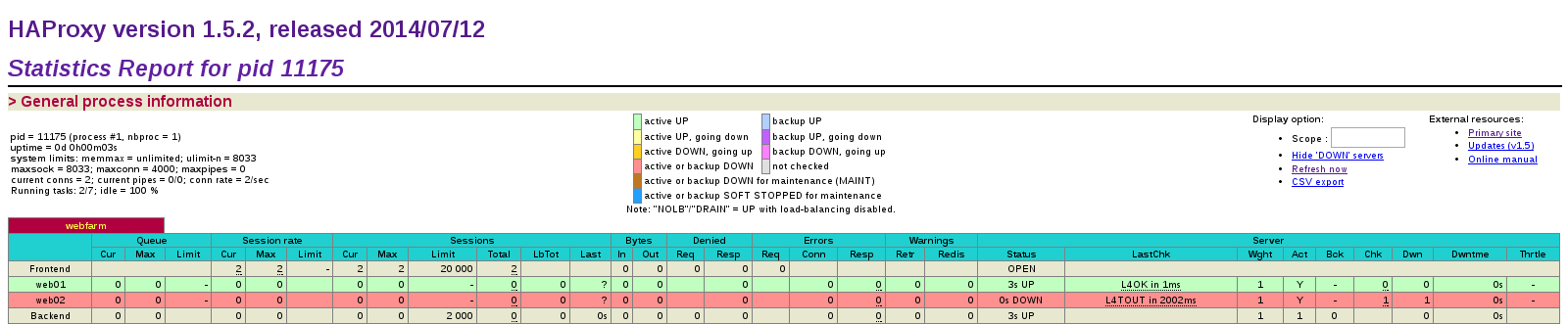
The line balance roundrobin defines the type of load balancing we will use. In this tutorial we will use simple round robin algorithm, which is fully sufficient for HTTP load balancing. HAProxy also offers other types of load balancing:
- leastconn: gives connections to the server with the lowest number of connections.
- source: hashes the source IP address, and divides it by the total weight of the running servers to decide which server will receive the request.
- uri: the left part of the URI (before the question mark) is hashed and divided by the total weight of the running servers. The result determines which server will receive the request.
- url_param: the URL parameter specified in the argument will be looked up in the query string of each HTTP GET request. You can basically lock the request using crafted URL to specific load balancer node.
- hdr(name): the HTTP header <name> will be looked up in each HTTP request and directed to specific node.
The line cookie LBN insert indirect nocache makes our load balancer store persistent cookies, which allows us to pinpoint which node from the pool is used for a particular session. These node cookies will be stored with a defined name. In our case, I used LBN, but you can specify any name you like. The node will store its string as a value for this cookie.
server web01 192.168.100.2:80 cookie node1 check server web02 192.168.100.3:80 cookie node2 check
The above part is the definition of our pool of web server nodes. Each server is represented with its internal name (e.g., web01, web02). IP address, and unique cookie string. The cookie string can be defined as anything you want. I am using simple node1, node2 ... node(n).
Start HAProxy
When you are done with the configuration, it's time to start HAProxy and verify that everything is working as intended.
Start HAProxy on Centos/RHEL
Enable HAProxy to be started after boot and turn it on using:
# chkconfig haproxy on # service haproxy start
And of course don't forget to enable port 80 in the firewall as follows.
Firewall on CentOS/RHEL 7:
# firewallcmd permanent zone=public addport=80/tcp # firewallcmd reload
Firewall on CentOS/RHEL 6:
Add following line into section :OUTPUT ACCEPT of /etc/sysconfig/iptables:
A INPUT m state state NEW m tcp p tcp dport 80 j ACCEPT
and restart iptables:
# service iptables restart
Start HAProxy on Debian
Start HAProxy with:
# service haproxy start
Don't forget to enable port 80 in the firewall by adding the following line into /etc/iptables.up.rules:
A INPUT p tcp dport 80 j ACCEPT
Start HAProxy on Ubuntu
Enable HAProxy to be started after boot by setting ENABLED option to 1 in /etc/default/haproxy:
ENABLED=1
Start HAProxy:
# service haproxy start
and enable port 80 in the firewall:
# ufw allow 80
Test HAProxy
To check whether HAproxy is working properly, we can do the following.
First, prepare test.php file with the following content:
<?php
header('Content-Type: text/plain');
echo "Server IP: ".$_SERVER['SERVER_ADDR'];
echo "nX-Forwarded-for: ".$_SERVER['HTTP_X_FORWARDED_FOR'];
?>
This PHP file will tell us which server (i.e., load balancer) forwarded the request, and what backend web server actually handled the request.
Place this PHP file in the root directory of both backend web servers. Now use curl command to fetch this PHP file from the load balancer (192.168.100.4).
$ curl http://192.168.100.4/test.php
When we run this command multiple times, we should see the following two outputs alternate (due to the round robin algorithm).
Server IP: 192.168.100.2 X-Forwarded-for: 192.168.100.4
Server IP: 192.168.100.3 X-Forwarded-for: 192.168.100.4
If we stop one of the two backend web servers, the curl command should still work, directing requests to the other available web server.
Summary
By now you should have a fully operational load balancer that supplies your web nodes with requests in round robin mode. As always, feel free to experiment with the configuration to make it more suitable for your infrastructure. I hope this tutorial helped you to make your web projects more resistant and available.
As most of you already noticed, this tutorial contains settings for only one load balancer. Which means that we have just replaced one single point of failure with another. In real life scenarios you should deploy at least two or three load balancers to cover for any failures that might happen, but that is out of the scope of this tutorial right now.
If you have any questions or suggestions feel free to post them in the comments and I will do my best to answer or advice.
Support Xmodulo
This website is made possible by minimal ads and your gracious donation via PayPal or credit card
Please note that this article is published by Xmodulo.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License. If you would like to use the whole or any part of this article, you need to cite this web page at Xmodulo.com as the original source.

Xmodulo © 2021 ‒ About ‒ Write for Us ‒ Feed ‒ Powered by DigitalOcean