How to create a cloud-based encrypted file system on Linux
Last updated on December 11, 2020 by Dan Nanni
Commercial cloud storage services such as Amazon S3 and Google Cloud Storage offer highly available, scalable, infinite-capacity object store at affordable costs. To accelerate wide adoption of their cloud offerings, these providers are fostering rich developer ecosystems around their products based on well-defined APIs and SDKs. Cloud-backed file systems are one popular by-product of such active developer communities, for which several open-source implementations exist.
S3QL is one of the most popular open-source cloud-based file systems. It is a FUSE-based file system backed by several commercial or open-source cloud storages, such as Amazon S3, Google Cloud Storage, Rackspace CloudFiles, or OpenStack. As a full featured file system, S3QL boasts of a number of powerful capabilities, such as unlimited capacity, up to 2TB file sizes, compression, UNIX attributes, encryption, snapshots with copy-on-write, immutable trees, de-duplication, hardlink/symlink support, etc. Any bytes written to an S3QL file system are compressed/encrypted locally before being transmitted to cloud backend. When you attempt to read contents stored in an S3QL file system, the corresponding objects are downloaded from cloud (if not in the local cache), and decrypted/uncompressed on the fly.
To be clear, S3QL does have limitations. For example, you cannot mount the same S3FS file system on several computers simultaneously, but only once at a time. Also, no ACL (access control list) support is available.
In this tutorial, I am going to describe how to set up an encrypted file system on top of Amazon S3, using S3QL. As an example use case, I will also demonstrate how to run rsync backup tool on top of a mounted S3QL file system.
Preparation
To use this tutorial, you will need to create an Amazon AWS account (sign up is free, but requires a valid credit card).
If you haven't done so, first create an AWS access key (access key ID and secret access key) which is needed to authorize S3QL to access your AWS account.
Now, go to AWS S3 via AWS management console, and create a new empty bucket for S3QL.
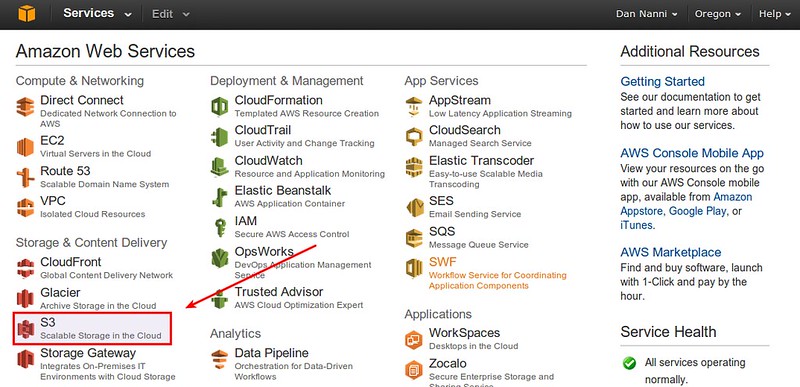
For best performance, choose a region which is geographically closest to you.
Install S3QL on Linux
S3QL is available as a pre-built package on most Linux distros.
On Debian, Ubuntu or Linux Mint:
$ sudo apt-get install s3ql
On Fedora:
$ sudo yum install s3ql
On Arch Linux:
On Arch Linux, use AUR.
Configure S3QL for the First Time
Create authinfo2 file in ~/.s3ql directory, which is a default S3QL configuration file. This file contains information about a required AWS access key, S3 bucket name and encryption passphrase. The encryption passphrase is used to encrypt the randomly-generated master encryption key. This master key is then used to encrypt actual S3QL file system data.
$ mkdir ~/.s3ql $ vi ~/.s3ql/authinfo2
[s3] storage-url: s3://[bucket-name] backend-login: [your-access-key-id] backend-password: [your-secret-access-key] fs-passphrase: [your-encryption-passphrase]
The AWS S3 bucket that you specify should be created via AWS management console beforehand.
Make the authinfo2 file readable to you only for security.
$ chmod 600 ~/.s3ql/authinfo2
Create an S3QL File System
You are now ready to create an S3QL file system on top of AWS S3.
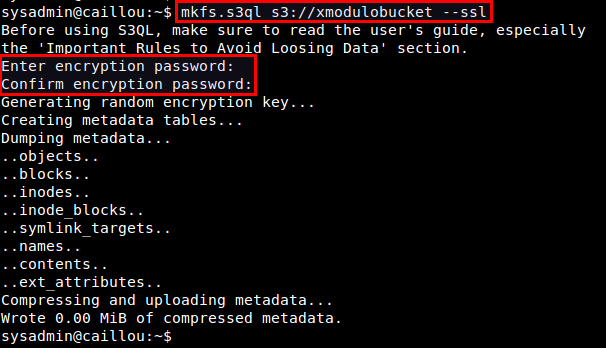
Use mkfs.s3ql command to create a new S3QL file system. The bucket name you supply with the command should be matched with the one in authinfo2 file. The --ssl option forces you to use SSL to connect to backend storage servers. By default, the mkfs.s3ql command will enable compression and encryption in the S3QL file system.
$ mkfs.s3ql s3://[bucket-name] --ssl
You will be asked to enter an encryption passphrase. Type the same passphrase as you defined in ~/.s3ql/autoinfo2 (under fs-passphrase).
If a new file system was created successfully, you will see the following output.
Mount an S3QL File System
Once you created an S3QL file system, the next step is to mount it.
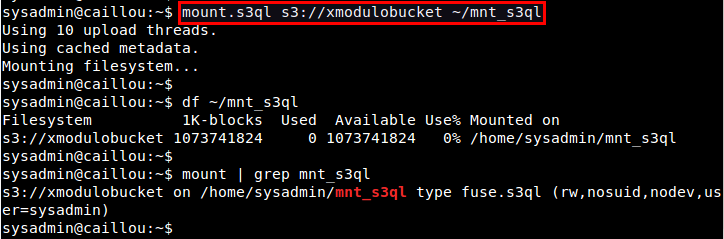
First, create a local mount point, and then use mount.s3ql command to mount an S3QL file system.
$ mkdir ~/mnt_s3ql $ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
You do not need privileged access to mount an S3QL file system. Just make sure that you have write access to the local mount point.
Optionally, you can specify a compression algorithm to use (e.g., lzma, bzip2, zlib) with --compress option. Without it, lzma algorithm is used by default. Note that when you specify a custom compression algorithm, it will apply to newly created data objects, not existing ones.
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
For performance reason, an S3QL file system maintains a local file cache, which stores recently accessed (partial or full) files. You can customize the file cache size using --cachesize and --max-cache-entries options.
To allow other users than you to access a mounted S3QL file system, use --allow-other option.
If you want to export a mounted S3QL file system to other machines over NFS, use --nfs option.
After running mount.s3ql, check if the S3QL file system is successfully mounted:
$ df ~/mnt_s3ql $ mount | grep s3ql
Unmount an S3QL File System
To unmount an S3QL file system (with potentially uncommitted data) safely, use umount.s3ql command. It will wait until all data (including the one in local file system cache) has been successfully transferred and written to backend servers. Depending on the amount of write-pending data, this process can take some time.
$ umount.s3ql ~/mnt_s3ql
View S3QL File System Statistics and Repair an S3QL File System
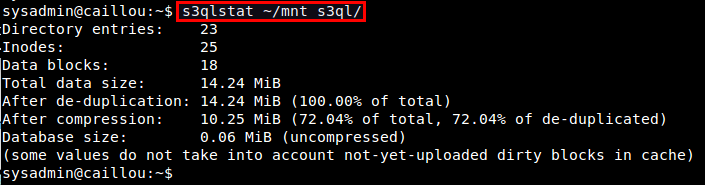
To view S3QL file system statistics, you can use s3qlstat command, which shows information such as total data/metadata size, de-duplication and compression ratio.
$ s3qlstat ~/mnt_s3ql
You can check and repair an S3QL file system with fsck.s3ql command. Similar to fsck command, the file system being checked needs to be unmounted first.
$ fsck.s3ql s3://[bucket-name]
S3QL Use Case: rsync Backup
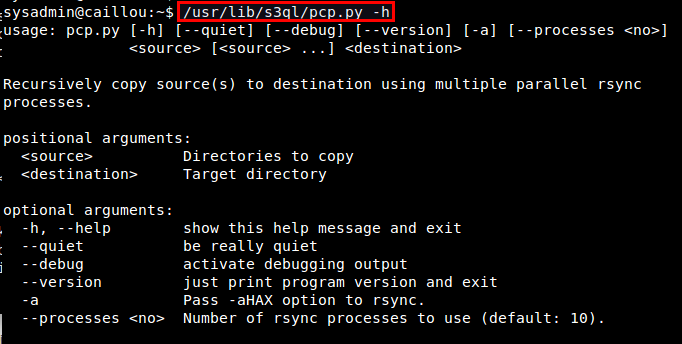
Let me conclude this tutorial with one popular use case of S3QL: local file system backup. For this, I recommend using rsync incremental backup tool especially because S3QL comes with a rsync wrapper script (/usr/lib/s3ql/pcp.py). This script allows you to recursively copy a source tree to a S3QL destination using multiple rsync processes.
$ /usr/lib/s3ql/pcp.py -h
The following command will back up everything in ~/Documents to an S3QL file system via four concurrent rsync connections.
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
The files will first be copied to the local file cache, and then gradually flushed to the backend servers over time in the background.
For more information about S3QL such as automatic mounting, snapshotting, immuntable trees, I strongly recommend checking out the official user's guide. Let me know what you think of S3QL. Share your experience with any other tools.
Support Xmodulo
This website is made possible by minimal ads and your gracious donation via PayPal or credit card
Please note that this article is published by Xmodulo.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License. If you would like to use the whole or any part of this article, you need to cite this web page at Xmodulo.com as the original source.

Xmodulo © 2021 ‒ About ‒ Write for Us ‒ Feed ‒ Powered by DigitalOcean